Uma taxonomia de AI agent skills
O post anterior foi a história. Este é a estrutura.
Depois de escrever umas trinta skills para um projeto, um padrão cristalizou. Cada skill pertence a um de seis tipos. Cada tipo responde uma pergunta diferente, roda num momento diferente, e tem um nível de risco apropriado diferente. Os nomes seguem uma forma consistente: <system>-<type>-<feature>. O agente usa essa forma para encontrar a skill certa sem eu precisar lembrar exatamente como chamei.
Esta é a taxonomia em que cheguei depois de uso real suficiente para que as categorias parecessem óbvias na hora de nomeá-las.
A convenção de nomes
Todo nome de skill é uma tripla: o sistema em que opera, o tipo de operação, e a feature específica.
<system>-<type>-<feature>Exemplos (genéricos):
agent-debug-checkpoint
agent-utils-scoring
agent-qa-replay-scenario
agent-delete-cache
agent-post-message
agent-guide-add-filter
ats-get-record
ats-search-records
slack-get-thread
slack-post-messageTrês coisas que essa nomenclatura te dá:
- Ordenável. Quando você lista a pasta de skills, skills relacionadas se agrupam alfabeticamente. Todas as skills de debug ficam juntas; todas as skills do agent ficam juntas.
- Previsível. Quando o agente (ou você) quer fazer algo, não precisa lembrar o nome exato. Pode chutar a forma — quero debugar algo sobre o checkpoint do agente, então provavelmente é
agent-debug-checkpoint— e geralmente vai acertar. - Pesquisável. Filtrar pelo segundo segmento te dá a fatia de skills para um tipo de trabalho. Mostra todas as skills de debug. Mostra todos os helpers de integração. A nomenclatura torna essas consultas triviais.
Essa terceira propriedade é a que o agente de IA realmente explora. Quando você pergunta “tem uma skill pra inspecionar o cache?” o agente escaneia nomes procurando cache mais debug ou delete, e localiza rápido. Um esquema de nomes plano sem tipos forçaria o agente a ler cada descrição; com tipos, ele pode fazer uma pré-seleção só pelo nome.
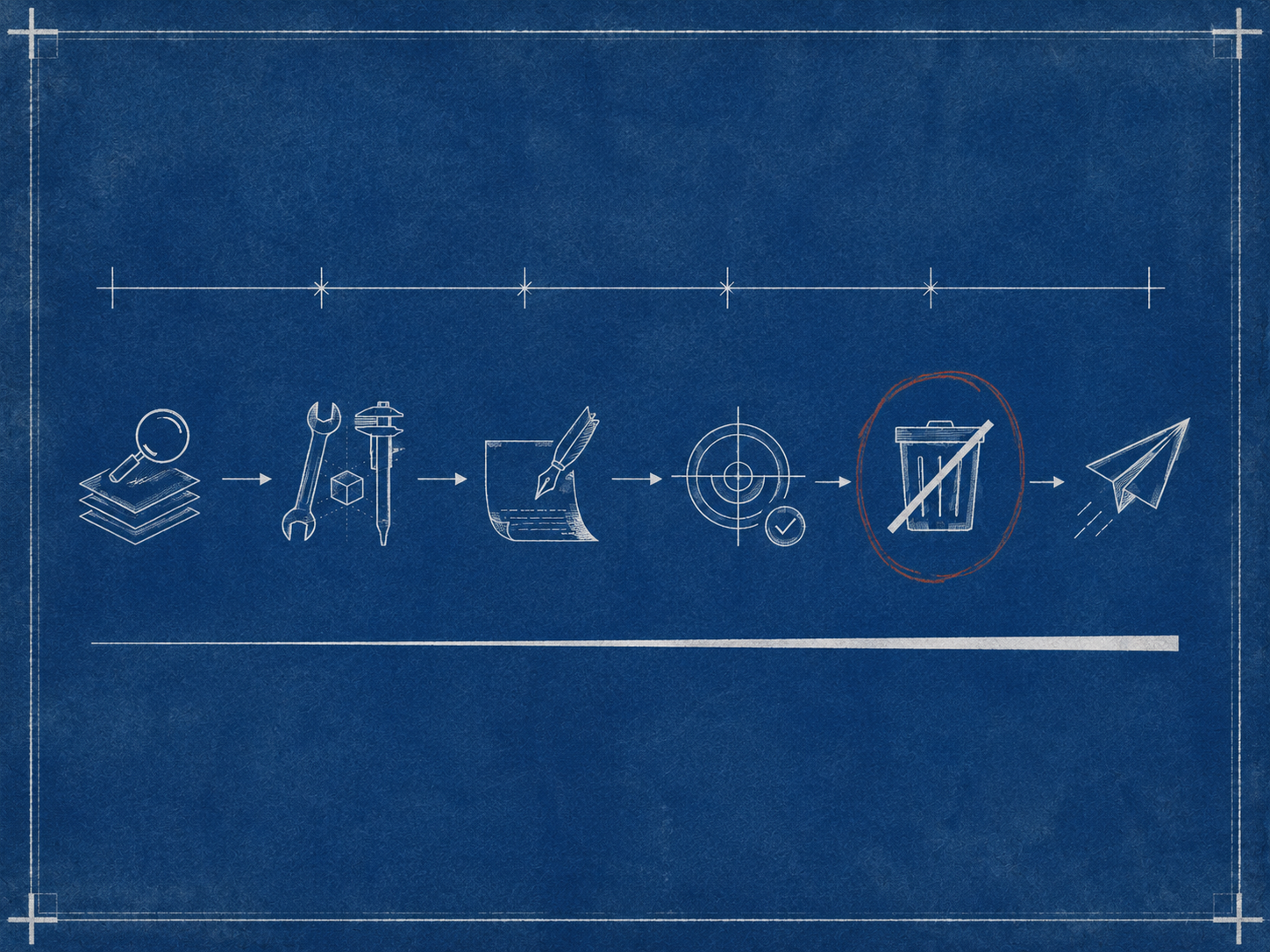
Os seis tipos
Cada tipo abaixo tem um trabalho específico. Vou passar por eles com os critérios que uso para decidir a qual tipo uma nova skill pertence.
debug — inspeção somente leitura
Trabalho: responder a pergunta “o que o sistema está realmente fazendo agora?”
Skills de debug lêem estado. Não modificam nada. Olham bancos de dados, caches, logs, threads de mensagens, traces — o que for necessário para entender o que acabou de acontecer ou o que é verdade no momento. O agente invoca uma skill de debug quando algo é inesperado e precisa de evidências antes de propor uma correção.
O perfil de risco é baixo. Uma skill de debug que dá errado imprime algo inútil ou falha de forma barulhenta. Não quebra nada.
O agente recorre a essas constantemente. Das minhas trinta e três skills, oito são de debug, e são o tipo mais usado por larga margem.
utils — exercitar uma peça de lógica com inputs customizados
Trabalho: “o que essa função faz se eu der esse input?”
Skills de utils são wrappers finos de linha de comando em torno de funções reais no codebase. Importam a função real e chamam com argumentos que você passa na linha de comando. O objetivo é exercitar uma peça específica de lógica isoladamente, sem levantar o sistema inteiro.
Exemplos concretos (genéricos):
agent-utils-scoring— roda a função de scoring num input de exemplo e imprime o score.agent-utils-query-builder— constrói uma string de query de busca a partir de critérios estruturados, imprime.agent-utils-skills— normaliza uma lista de nomes de skills e mostra a forma canônica.
O perfil de risco é baixo — são somente leitura por construção. O valor é alto — quando algo está dando errado, poder chamar uma peça do pipeline diretamente é o caminho mais rápido para localizar o bug.
guide — procedimento multi-step para uma mudança recorrente
Trabalho: “qual é o playbook pra adicionar a feature X?”
Skills de guide são a coisa mais próxima de documentação na gaveta de skills. Descrevem uma mudança multi-arquivo que você às vezes precisa fazer — adicionar um novo filtro a um pipeline de busca, conectar um novo formatter de saída, adicionar um novo intent — com um checklist de arquivos para tocar e a ordem para tocá-los.
Frequentemente uma skill de guide não tem script nenhum. O corpo é a skill. O agente lê o procedimento, percorre no change atual, e o desenvolvedor revisa cada passo.
O perfil de risco depende do que o guide muda. O procedimento em si é só um checklist; as edições reais que o agente faz seguindo o procedimento são o que carrega o risco. Por isso guides são tipicamente usados em modo de planejamento ou revisão, não como automação fire-and-forget.
qa — regressão e replay
Trabalho: “isso ainda funciona do jeito que funcionava?”
Skills de QA são voltadas para teste. Executam um cenário, capturam a saída e respondem uma pergunta: a coisa que mudei quebrou o que já estava funcionando? Skills de debug inspecionam estado ao vivo; skills de QA repetem cenários de teste.
post — escrever algo
Trabalho: “manda isso pra um sistema.”
Skills de post fazem algo com efeito colateral — escrevem num banco de dados, enviam uma mensagem, atualizam um registro. São deliberadamente separadas de debug e utils para que você não invoque acidentalmente uma escrita quando queria uma leitura.
Essa separação é a decisão de design mais importante que tomei na taxonomia. Misturar leituras e escritas num mesmo tipo significa que um typo no nome da skill pode custar dados. Com debug e post como prefixos diferentes, “eu rodei um debug ou um post?” é um olhar pro nome. A carga cognitiva vai pra zero.
delete — destrutivo
Trabalho: “remove isso.”
Delete é seu próprio tipo e não um subtipo de post pela mesma razão: uma camada extra de separação baseada em nome entre “estou lendo”, “estou escrevendo” e “estou deletando.” Uma skill de delete é o único tipo que deveria te fazer pausar antes de invocar. O nome sendo seu próprio segmento torna essa pausa barata de impor.
Das trinta e três skills, exatamente uma é de delete. Isso é mais ou menos certo. Operações destrutivas devem ser raras e explícitas.
As integrações sem tipo
Nem toda skill se encaixa no padrão tipado. Existe uma categoria de skills que são helpers puros em torno de um sistema externo — buscar um registro por ID, postar uma mensagem, listar o conteúdo de uma thread. Essas usam uma convenção de nomes diferente:
<system>-<verb>-<resource>Então ats-get-record, ats-search-records, slack-get-thread, slack-post-message. O verbo é a operação, não o tipo. Essas são as únicas skills que tenho que não seguem o padrão tipado do agent, e não precisam seguir. Encapsulam uma API externa específica de forma testada e opinativa e são reutilizadas em muitas skills de nível mais alto.
Como os tipos se compõem durante uma sessão real
Observando eu mesmo debugar algo que quebrou, os tipos aparecem numa ordem previsível.
- Algo está errado. O agente recorre a uma skill de
debug: lê o estado ao vivo, entende o que o sistema realmente fez. - O estado confirma uma hipótese. O agente recorre a uma skill de
utils: re-executa uma única função com o input específico que causou o problema. - A correção fica óbvia. O agente edita arquivos (sem skill necessária pra essa parte — edições de código são diretas).
- Depois da correção, o agente roda uma skill de
qapara confirmar que o cenário quebrado agora funciona. - Se a correção invalida resultados em cache, o agente roda uma skill de
deletepara limpá-los. - Se a correção precisa ser comunicada, uma skill de
postvolta pro chat da equipe.
Seis skills, seis tipos, um loop completo. A convenção de nomes transforma “debugar uma coisa” de uma série de procedimentos memorizados em algo mais parecido com um vocabulário que o agente já fala. A sobrecarga cognitiva desaparece.

Decisões de design que valeram a pena
Algumas escolhas, em retrospecto, fizeram a maior parte do trabalho.
Separar leituras de escritas pelo nome. Colocar debug e post em segmentos de nome diferentes — em vez de, digamos, ter uma única skill agent-cache que faz ambos — é a melhor decisão desta taxonomia. Tornou escritas acidentais essencialmente impossíveis.
Deixar skills de integração quebrarem o padrão. Forçar toda skill no formato <system>-<type>-<feature> teria tornado os helpers de integração estranhos. ats-debug-record é um nome pior que ats-get-record. Permitir dois padrões de nomenclatura foi mais limpo que overfitting a um.
Apontar toda skill para o código-fonte vivo. Skills são documentação; documentação defasa. Cada corpo de skill tem uma pequena seção “Backend reference” apontando para os arquivos reais no codebase que implementam a funcionalidade subjacente. Quando a skill está errada, o agente tem um fallback que é correto por construção.
Manter a descrição focada no quando, não no o quê. Descrições iniciais diziam “This skill clears the cache.” Esse é o o quê. O agente não precisa disso — ele pode ver o nome. As descrições que funcionaram diziam “Use when stale cached results cause incorrect scores after a scoring rule change.” Isso diz ao agente quando recorrer à skill, que é a pergunta realmente útil.
Decisões de design que não valeram a pena
Algumas que tentei e voltei atrás.
Sub-tipos. Tentei brevemente debug-cache, debug-state, debug-trace como sub-tipos próprios com suas próprias convenções. O benefício era pequeno; o custo cognitivo era real. Voltei a um tipo debug plano com nomes de feature descritivos.
Forçar toda skill a ter um script. Algumas skills genuinamente não precisam de código executável — guides especialmente. Insistir num script para toda skill produziu scripts hello-world vazios que atrapalhavam. Deixar o corpo em si ser a skill foi mais simples.
Como isso se parece pra outra pessoa
Se você está partindo de zero skills e considerando escrever algumas, a taxonomia não é a parte por onde começar. A taxonomia emergiu depois que eu tinha escrito skills suficientes para sentir as categorias. Tentar projetar as categorias antes de ter as skills é o tipo de abstração prematura que produz baldes vazios.
O que eu realmente sugeriria:
- Escreva sua primeira skill na segunda vez que fizer algo. Não se preocupe com o tipo ou a nomenclatura.
- Escreva mais algumas, na forma que couber em cada uma.
- Lá pela skill dez ou mais, pause. Olhe os nomes. Você vai notar que alguns estão lendo estado, alguns estão rodando scripts com inputs, alguns estão percorrendo procedimentos, alguns estão escrevendo em sistemas. As categorias já estão lá, latentes no trabalho.
- Aí defina uma convenção de nomes. Renomeie as skills que tem. A renomeação é barata se feita uma vez; fica cara se esperar até ter cinquenta.
Essa é a ordem. Skills primeiro, taxonomia depois. A estrutura é consequência do trabalho real, não o contrário.